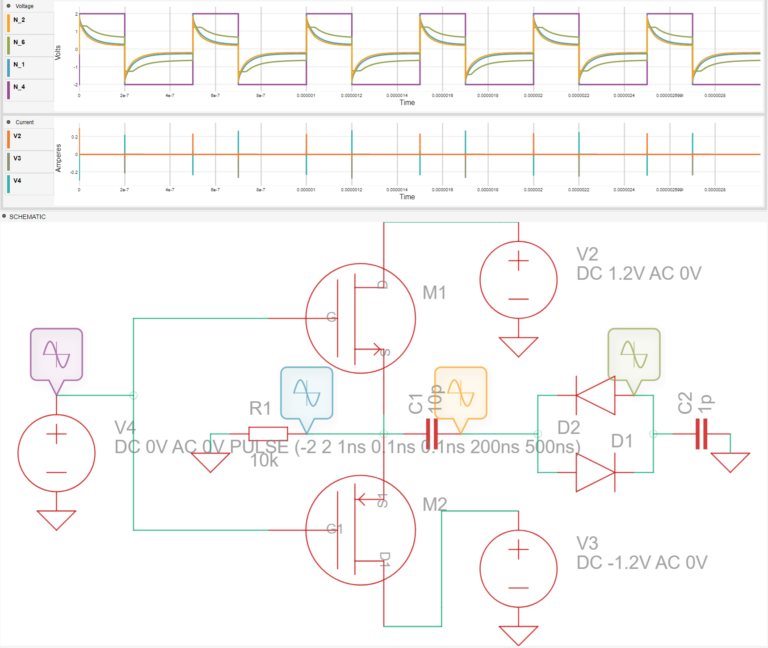
changed ram to dual port ram. every instruction is now 1 cycle, including ram load/store. simplified circuit in general. rearranged regX, regY and regZ dual port ram single-line modules to test octo-line array input/output mode. simplified mux risc core to single circuit running only single core with direct ram loading and full 64k x 64bit registry and 128MB unified ram.
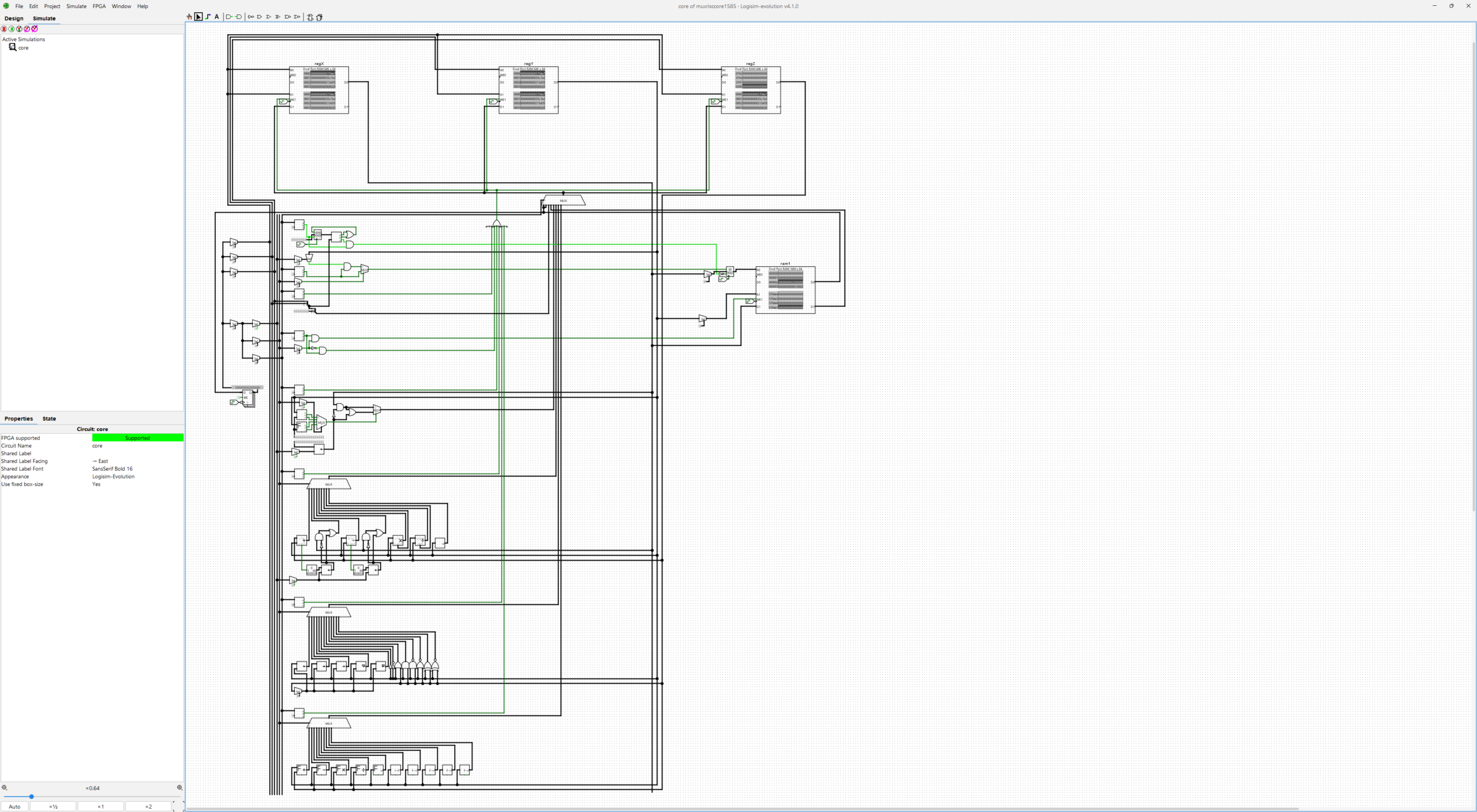
RISC core-gate instruction set architecture (64-bit variation of RISC-V):
Each core contains 2x 32k core-rail and 1-to-1 routing lines, 512 io-lines, and 1024 registers (64k).
Each core contains 24-bit addressed 128MB ram, including rom, ram, touch-display ram, and nand nvram.
Every instruction uses/operates on full 64-bit register values always, and runs in 1 cycle.
Instruction high bits can contain specific simple variations of instructions.
Each 64-bit instruction is formed from 16-bit [regX regY regZ insT] parameters.
insT parameter is formed from 8-4-4-bit [bitI insV insO] parameters.
Estimated logic transistors per core is 200k making 32k cores about 6.4 billion.
Estimated ram transistors per core is 4million 512KB and 128billion total 16GB.
Estimated compute 64-bit teraops at 5GHz per core is 5gops and 160tops total.
Opcode | Instruction | Name | Description
----------------------------------------------------------------------------------------------------
any | ## | Any Raw Data | direct data line 64-bit value
0 | nopYZ | No Operation | no operation sleep constant regYZ cycles
[] empty line or white space line
// comment line
1 | jmpXY | Jump Destination | jump to regX if regYb[bitI] is set
jmpcXY insV=0 jump to regX if regYb[bitI] is set
jmpuXY insV=1 unconditional jump to regX
2 | ldiXYZ | Load 32-bit Uint | load regX with constant regYZ
3 | memXY | Memory Double | store/load[insV] regX at memory[regY]
memrXY insV=0 load
memwXY insV=1 store
4 | cmpXY | Compare to Zero | clear regXb[bitI], set to 1 if regY comp[insV]
cmpeXY insV=0 integer equal to
cmplXY insV=1 integer less than
cmpefXY insV=2 float equal to
cmplfXY insV=3 float less than
5 | intXYZ | ALU Int Operation | store integer op[insV] regY regZ to regX
addXYZ insV=0 integer add
addoXYZ insV=1 integer add overflow bit regXb[bitI]
subXYZ insV=2 integer subtract
subbXYZ insV=3 integer subtract borrow bit regXb[bitI]
mulXYZ insV=4 integer multiply
muloXYZ insV=5 integer multiply overflow
divXYZ insV=6 integer divide
divrXYZ insV=7 integer divide remainder
negXYZ insV=8 integer negate
6 | bitXYZ | ALU Bit Operation | store bitwise op[insV] regY regZ to regX
shlXYZ insV=0 bitwise shift left regZ bits
shrXYZ insV=1 bitwise shift right regZ bits
sharXYZ insV=2 bitwise shift arithmetic right regZ bits
rotlXYZ insV=3 bitwise rotate left regZ bits
rotrXYZ insV=4 bitwise rotate right regZ bits
copyXYZ insV=5 bitwise copy
notXYZ insV=6 bitwise not
orXYZ insV=7 bitwise or
andXYZ insV=8 bitwise and
nandXYZ insV=9 bitwise nand
norXYZ insV=A bitwise nor
xorXYZ insV=B bitwise xor
xnorXYZ insV=C bitwise xnor
7 | flpXYZ | ALU Flp Operation | store float op[insV] regY regZ to regX
addfXYZ insV=0 float add
subfXYZ insV=1 float subtract
mulfXYZ insV=2 float multiply
divfXYZ insV=3 float divide
negfXYZ insV=4 float negate
itfXYZ insV=5 integer to float
ftinXYZ insV=6 float to integer nearest
ftidXYZ insV=7 float to integer round down
ftiuXYZ insV=8 float to integer round up
ftitXYZ insV=9 float to integer truncateExample looping test assembly code source and binary:
source listing | binary | explanation
----------------------------------------------------------------------------------------------------
[] | 0000000000000000 | empty line
// empty line | 0000000000000000 | comment line
nop 00000200 | 0000000002000000 | no operation sleep 512+1 cycles
ldi 0000 00000001 | 0000000000010002 | load register 0 with value 0x1, current fibonacci number
ldi 0001 00000001 | 0001000000010002 | load register 1 with value 0x1, previous fibonacci number
ldi 0002 00000000 | 0002000000000002 | load register 2 with value 0x0, previous+ fibonacci number
ldi 0003 00000000 | 0003000000000002 | load register 3 with value 0x0, for loop index from 0
ldi 0004 00000020 | 0004000000200002 | load register 4 with value 0x20, for loop less than 32
ldi 0005 00000018 | 0005000000180002 | load register 5 with value 0x18, ram store start index
ldi 0006 00000001 | 0006000000010002 | load register 6 with value 0x1, constant 0x1 add and jump
ldi 0007 0000000C | 00070000000C0002 | load register 7 with value 0xC constant jump address
ldi 000b 00000000 | 000b000000000002 | load register 11 with value 0x0 constant jump address
copy 0002 0001 | 0002000100000056 | copy register 1 to register 2
copy 0001 0000 | 0001000000000056 | copy register 0 to register 1
add 0000 0001 0002 | 0000000100020005 | store addition of register 1 and register 2 to register 0
add 000a 0005 0003 | 000a000500030005 | store addition of register 5 and register 3 to register 10
memw 0000 000a | 0000000a00000013 | store register 0 to register 10 memory location
add 0003 0003 0006 | 0003000300060005 | store addition of register 3 and register 6 to register 3
sub 0008 0003 0004 | 0008000300040025 | store subtract of register 3 and register 4 to register 8
cmpl 0009 0008 | 0009000800000014 | clear register 9 bit 0, set if register 8 int less than 0
jmpc 0007 0009 | 0007000900000001 | jump to register 7 if register 9 bit 0 is set
jmpu 000b | 000b000000000011 | unconditional jump to register 11
## A123456789ABCDEF | a123456789abcdef | custom data segment with any instruction or dataExample looping test assembly to c-code approximate:
while(true) { // infinite while loop
register<0> long fib1 = 0x1; // init fib1 with register 0 64-bit long integer value 1
register<1> long fib2 = 0x1; // init fib2 with register 1 64-bit long integer value 1
register<2> long fib3 = 0x0; // init fib3 with register 2 64-bit long integer value 0
register<3> long i = 0; // init loop i with register 3 64-bit long integer value 0
register<4> long imax = 32; // init loop imax with register 4 64-bit long integer value 32
register<5> long *mem = 0x18; // init mem as 64-bit long integer pointer at address 0x18
for (;i<imax;i++) { // for loop 64-bit long integer i index value from 0 to 31
fib3 = fib2; // copy old fib2 value to fib3
fib2 = fib1; // copy old fib1 value to fib2
fib1 = fib2 + fib3; // calculate new fib1 value by adding fib2 and fib3
mem[i] = fib1; // store fib1 value to mem location +i index
} // for loop close
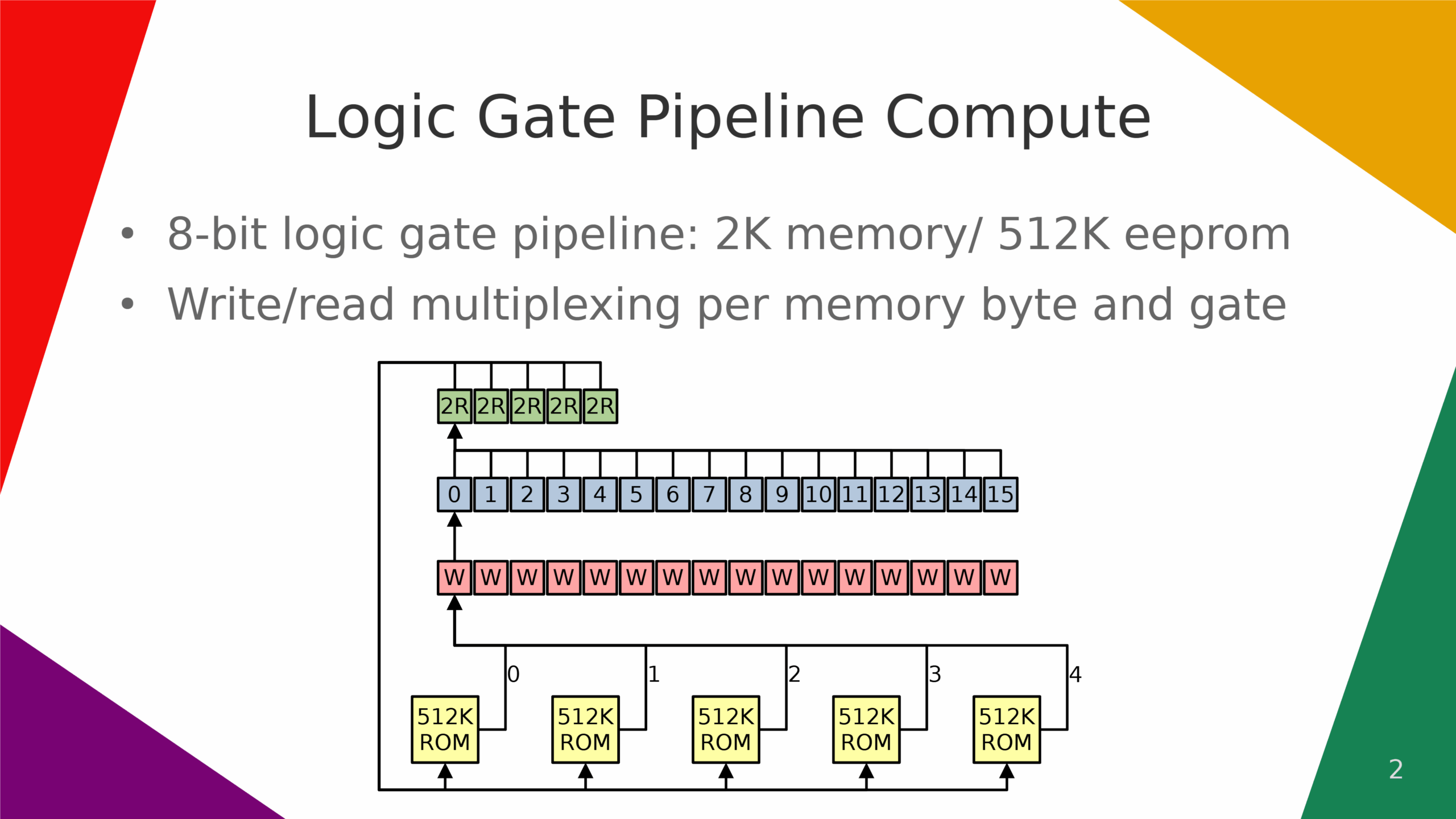
} // infinite while loop closegate pipeline compute implemented as risc-v compute cores grid routing network. each core has their own 16-bit x 64bit = 512KB internal compute cache, but all middle level memory based caches are replaced with grid routing network for much higher bandwidth. each gate core has 2x 64-bit wide input and 1x 64-bit wide output.
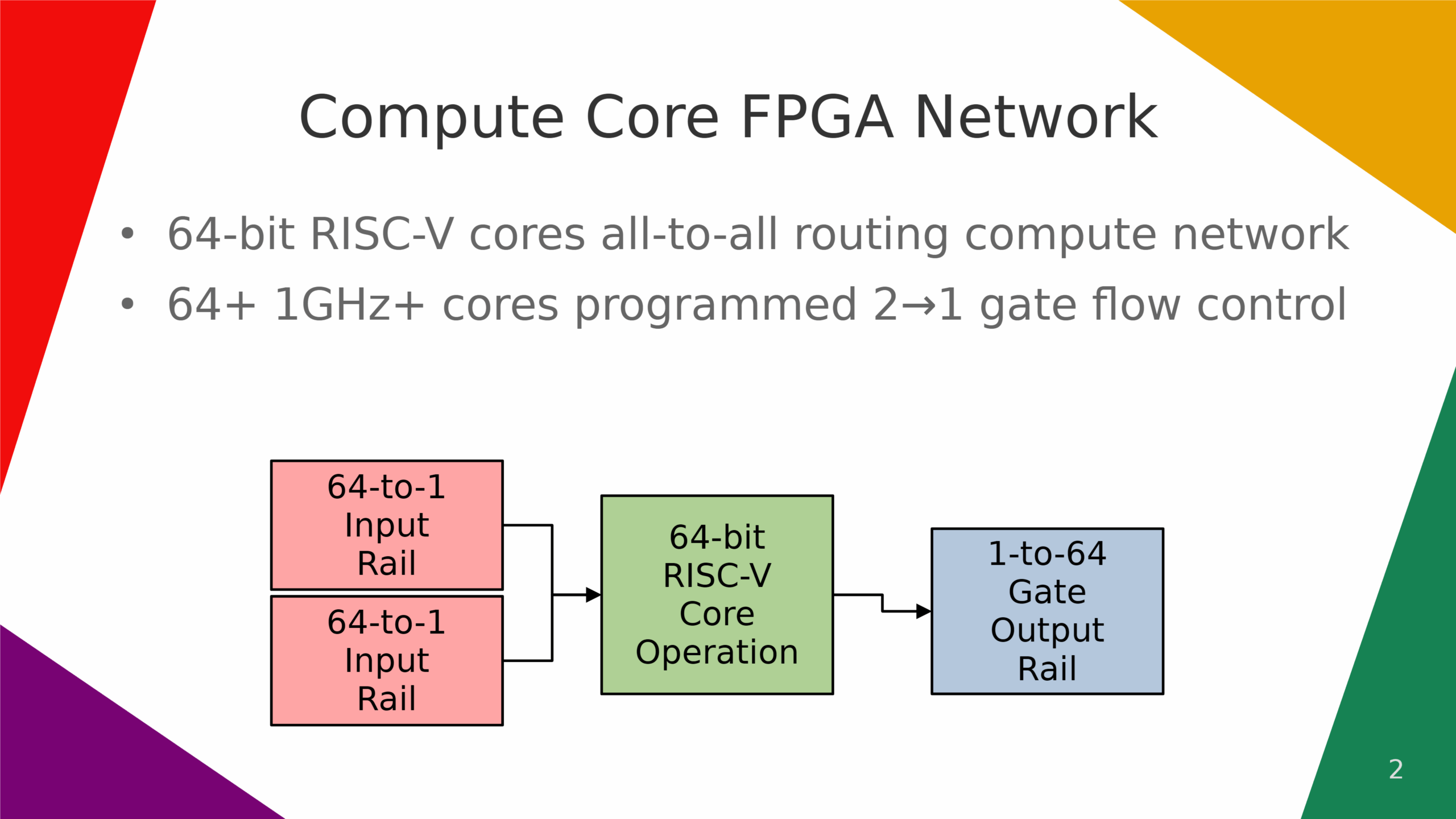
gate pipeline compute architecture based on pre-computed nor-memory stored 8-bit values fpga architecture.
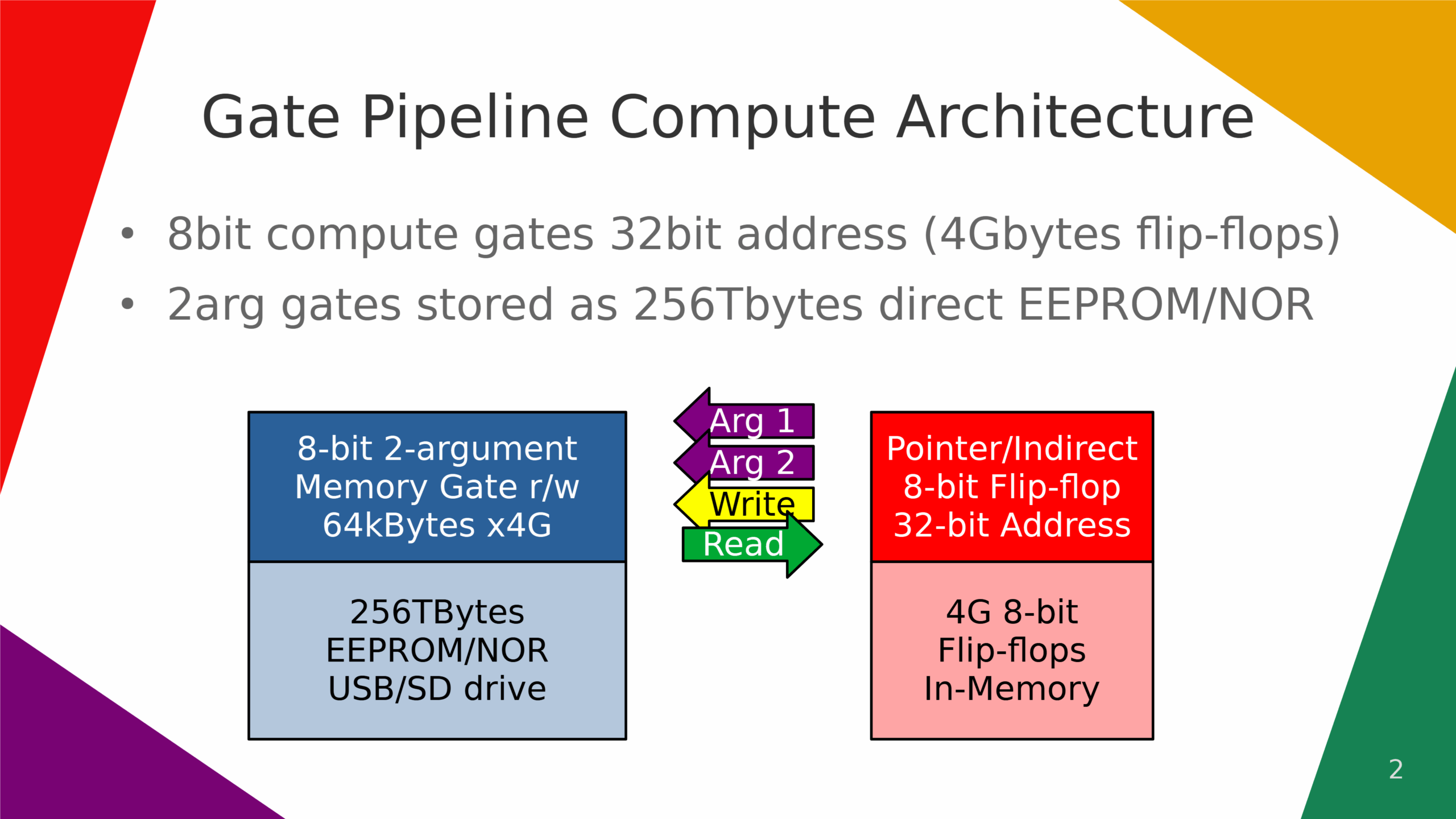
Logic gate pipeline compute.
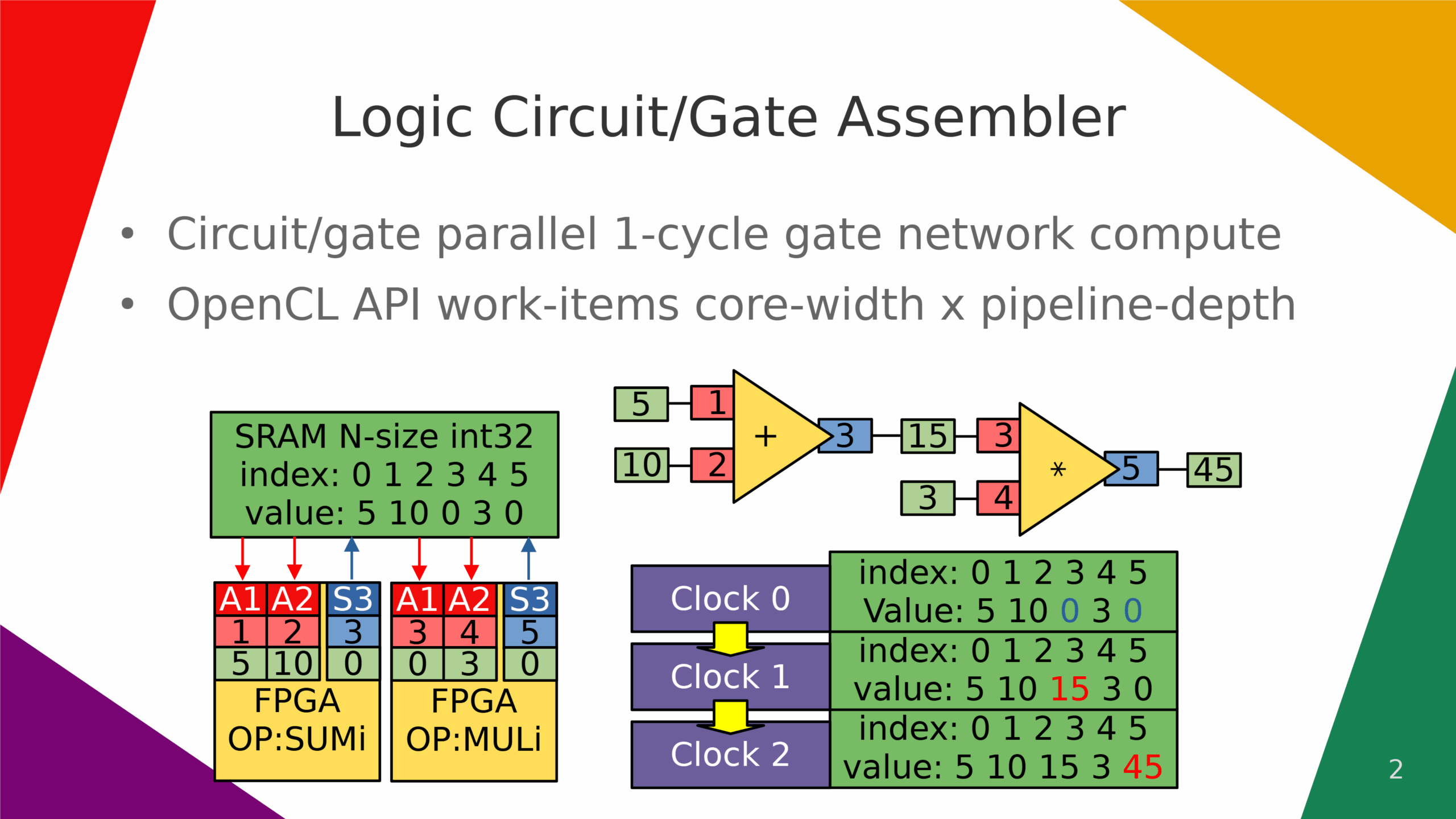
Logic circuit/gate assembler.
MISC Compute Chip